Scry Design Diff Eval: Measuring VLMs as Mobile UI Regression Reviewers
Scry Design Diff Eval is a benchmark built to evaluate vision-language models on the task of mobile UI diff review.
Each example pairs a reference screen with a generated implementation screen and uses human-drawn selection boxes plus explicit defect tags.
The current release contains a full 311-pair benchmark.
Abstract
Vision-language models are increasingly used to inspect generated interfaces, but practical UI review is not just image similarity. A useful reviewer must identify developer-actionable defects: missing components, wrong icons, typographic drift, incorrect state styling, and layout regressions.
We introduce Scry Design Diff Eval, a benchmark built from human-reviewed mobile UI pairs. Each example contains a reference screenshot and a generated implementation screenshot. Human annotations contain explicit defect tags and normalized selection boxes on one or both images. The primary metric is known-issue recall: the fraction of human-tagged issues recovered by a model with both a matching tag and overlapping selection box.
On the full 311-pair benchmark with 557 tagged issues, the highest-recall runs recover roughly two fifths of known issues. Kimi K2.7 Code with Together retry recovery obtains 38.2% known-issue recall, Gemini 3.5 Flash obtains 37.5%, and Codex GPT-5.5 xhigh obtains 37.3%. Gemini 3.5 Flash is the strongest balanced result in this snapshot, with 20.2% diagnostic precision and the best issue F1 among high-recall models. These results suggest that current VLM endpoints can identify many mobile UI defects, but still miss most known human issues and over-flag most no-diff controls under a strict tag-and-box matching protocol.
1. Introduction
Generated UI workflows increasingly produce screenshots that must be compared against product references or design targets. A reviewer needs to do more than notice that two images differ. They need to say what changed, where it changed, and whether the change matters to a developer.
Traditional visual regression testing emphasizes pixels or perceptual image distance. Those tools are valuable, but they are brittle for product review: harmless rendering differences can create large pixel deltas, while serious regressions can be localized and semantically subtle. A button can have the wrong selected state, an icon can be swapped for a similar asset, or a missing row can break the screen without dominating a global image metric.
Vision-language models appear well suited to this setting because they can jointly inspect images and produce structured text.
The benchmark asks a model to compare a reference mobile screenshot with a generated implementation screenshot and return a list of UI defects with tags and selection boxes. The scoring protocol is recall-first because the human annotations are known positives, not exhaustive negatives. Extra model findings may be valid and are reported diagnostically rather than used to reduce the primary score.
The main contributions are:
- A mobile UI image-diff benchmark built from human-reviewed generated screens.
- A structured annotation format with explicit defect tags and normalized boxes.
- A deterministic tag-and-box judge for known-issue recall.
3. Dataset Construction
The source annotation tool presents reviewers with two images:
- Image A: the reference target, usually a mobile app screenshot.
- Image B: the generated implementation screenshot.
Reviewers draw a selection box on Image A, Image B, or both. They then attach one or more defect tags. Notes are supported by the annotation tool, but notes are missing on many annotations and are not used for primary v1 scoring.
The current local snapshot starts from completed reviewed screens. The dataset builder keeps only annotations that have explicit tags and at least one usable selection box. Screens with no scored tagged issues become no-tagged controls. This means no-tagged controls are a practical proxy, not a guarantee that the screen is defect-free.
| Quantity | Count |
|---|---|
| Eval pairs | 311 |
| Visual-diff pairs | 234 |
| No-tagged controls | 77 |
| Counted tagged issues | 557 |
The dataset uses issue-density buckets:
| Split | Definition | Full-set pairs |
|---|---|---|
single_issue | 1 tagged issue | 107 |
multi_issue | 2-3 tagged issues | 80 |
dense_issue | 4 or more tagged issues | 47 |
no_diff | 0 scored tagged issues | 77 |
These buckets are not manually curated difficulty labels. They measure annotation density. A future version could add a separate curated difficulty field.
The most common full-set tags are Icon/Nav, Color/Background, Spacing/Layout, Shape/Size, Missing Content, and Typography. The tag distribution is intentionally not balanced because it reflects the actual annotation workflow.
4. Task Definition
Given a reference screenshot and a generated screenshot, a model must return a JSON object with an issues array. Each issue describes one visible UI defect.
{
"issues": [
{
"labels": ["Icon/Nav"],
"note": "The bottom navigation icon differs from the reference.",
"box_a": {"x": 0.10, "y": 0.90, "w": 0.12, "h": 0.07},
"box_b": {"x": 0.10, "y": 0.90, "w": 0.12, "h": 0.07},
"confidence": 0.80
}
]
}Boxes are normalized to the image size, with x, y, w, and h in the range 0 to 1. A model may supply a box on either image or both images. The scorer only uses boxes that are present and valid.
The desired output is not a paragraph describing the screen. It is a structured issue list that can be compared against known human annotations and inspected by a developer.
5. Scoring Protocol
The primary score is known-issue recall. A model issue matches a human issue when both conditions hold:
- The model issue and human issue share at least one explicit defect tag.
- The model box overlaps the human box on the same image side with IoU >= 0.10.
Matching is one-to-one: each human issue can be matched once, and each model issue can be matched once. This prevents a single broad prediction from recovering multiple annotations unless it is represented as multiple issues.
| Metric | Definition | Role |
|---|---|---|
| Known-Issue Recall | Matched human issues / all human issues | Primary |
| Diff Screen Recall | Visual-diff screens with at least one matched issue / all visual-diff screens | Diagnostic |
| No-Tagged Flag Rate | No-tagged screens where the model predicts at least one issue / all no-tagged screens | Diagnostic |
| Diagnostic Precision | Matched model issues / all model issues | Diagnostic |
| Unmatched Predicted Issues | Model issues that do not match a known human issue | Diagnostic |
The protocol is recall-first because human annotations are not exhaustive. Extra model findings can be valid, especially on no-tagged controls. They are surfaced for review rather than directly penalizing the primary metric.
The deterministic judge is intentionally simple and auditable. It does not use a separate VLM to decide whether an extra finding is valid.
6. Experimental Setup
The study began with open or openly available VLM endpoints and was later expanded with two hosted high-recall comparators. The 60-row pilot is stratified as 15 examples per bucket: no-tagged controls, single-issue screens, multi-issue screens, and dense-issue screens. The full benchmark contains 311 pairs and is evaluated with the same deterministic tag-and-box judge.
| Model | Provider | Status |
|---|---|---|
minimax/minimax-m3 | OpenRouter | 60-row pilot complete; full 311-row run complete |
google/gemma-4-31b-it | OpenRouter | 60-row pilot complete; full 311-row run complete |
google/gemma-4-26b-a4b-it | OpenRouter | 60-row pilot complete; full 311-row run complete |
moonshotai/kimi-k2.7-code | OpenRouter + Together retry recovery | 60-row pilot complete; full 311-row run complete after retrying failed OpenRouter rows |
gemini-3.5-flash | Google Gemini API, OpenAI-compatible endpoint | Full 311-row run complete |
codex-cli/gpt-5.5 xhigh | Codex CLI | Full 311-row run complete |
Three static controls validate the pipeline:
always-no-issue: predicts no issues.always-generic-issue: predicts one vague issue for every pair.oracle-notes: copies ground-truth tags and boxes.
The oracle control should score 100%, confirming that the tag-and-box judge can recover exact known annotations. The always-generic control should not recover issues, confirming that vague screen-level reporting is insufficient.
Kimi K2.7 Code requires special reporting. After OpenRouter-side retry passes, the OpenRouter full artifact still contained only 169 valid rows, 129 empty outputs, and 13 malformed outputs. We retried the 142 failed rows through Together AI using the same model ID and merged the valid retry outputs back into the full prediction file. The final Kimi artifact therefore measures the model with recovery, not the raw OpenRouter route alone.
7. Results
7.1 Static Controls
| Model | Known-Issue Recall | Diff Screen Recall | No-Tagged Flag Rate | Diagnostic Precision |
|---|---|---|---|---|
| always-no-issue | 0.0% | 0.0% | 0.0% | 0.0% |
| always-generic-issue | 0.0% | 0.0% | 100.0% | 0.0% |
| oracle-notes | 100.0% | 100.0% | 0.0% | 100.0% |
7.2 60-Row Hosted Pilot
The 60-row pilot contains 45 visual-diff screens, 15 no-tagged controls, and 140 scored human tagged issues. Coverage counts input rows with a prediction row present, including empty or malformed model outputs.
| Model | Coverage | Known-Issue Recall | Diff Screen Recall | No-Tagged Flag Rate | Diagnostic Precision |
|---|---|---|---|---|---|
| MiniMax M3 | 60/60 | 16.4% (23/140) | 40.0% (18/45) | 86.7% (13/15) | 10.8% (23/212) |
| Gemma 4 31B | 60/60 | 11.4% (16/140) | 28.9% (13/45) | 100.0% (15/15) | 11.0% (16/146) |
| Gemma 4 26B A4B | 60/60 | 15.7% (22/140) | 31.1% (14/45) | 100.0% (15/15) | 12.1% (22/182) |
| Kimi K2.7 Code | 60/60 | 23.6% (33/140) | 48.9% (22/45) | 60.0% (9/15) | 19.6% (33/168) |
Kimi K2.7 Code has the highest scored known-issue recall in the pilot after retrying failed rows, while MiniMax M3 leads among the fully parseable hosted baselines. Gemma 4 31B and Gemma 4 26B A4B flag all 15 no-tagged controls, which shows that they are recall-leaning and noisy under the current no-tagged proxy.
Kimi K2.7 Code should be interpreted primarily as a route and format-stability result. After the 600-second retry pass, 42 of 60 rows returned valid JSON under the tested route; 16 rows were empty and 2 rows were invalid JSON.
7.3 Full 311-Row Results
The full benchmark contains 311 pairs: 234 visual-diff screens, 77 no-tagged controls, and 557 scored human issues. All full-run prediction artifacts are fully parseable except MiniMax M3, which has one malformed output row out of 311.
| Model | Coverage | Known-Issue Recall | Diff Screen Recall | No-Tagged Flag Rate | Diagnostic Precision | Issue F1 |
|---|---|---|---|---|---|---|
| Kimi K2.7 Code + Together recovery | 311/311 | 38.2% (213/557) | 65.8% (154/234) | 100.0% (77/77) | 15.9% (213/1,340) | 22.5% |
| Gemini 3.5 Flash | 311/311 | 37.5% (209/557) | 62.4% (146/234) | 96.1% (74/77) | 20.2% (209/1,033) | 26.3% |
| Codex GPT-5.5 xhigh | 311/311 | 37.3% (208/557) | 64.5% (151/234) | 98.7% (76/77) | 13.6% (208/1,530) | 19.9% |
| MiniMax M3 | 311/311 | 21.9% (122/557) | 40.6% (95/234) | 93.5% (72/77) | 11.5% (122/1,065) | 15.0% |
| Gemma 4 26B A4B | 311/311 | 20.3% (113/557) | 35.9% (84/234) | 85.7% (66/77) | 12.4% (113/913) | 15.4% |
| Gemma 4 31B | 311/311 | 17.8% (99/557) | 32.5% (76/234) | 79.2% (61/77) | 13.3% (99/744) | 15.2% |
Kimi K2.7 Code with recovery has the highest known-issue recall, but it flags every no-tagged control. Gemini 3.5 Flash is the strongest balanced result in this snapshot: it is only four matched issues behind Kimi, while producing 307 fewer predicted issues and the highest F1 among the high-recall models. Codex GPT-5.5 xhigh is effectively tied with the two leaders on recall, but is the most verbose high-recall run.
7.4 Defect-Density Breakdown
| Model | Single-Issue Recall | Multi-Issue Recall | Dense-Issue Recall |
|---|---|---|---|
| Kimi K2.7 Code + Together recovery | 53.3% | 46.3% | 26.2% |
| Gemini 3.5 Flash | 49.5% | 40.0% | 30.8% |
| Codex GPT-5.5 xhigh | 50.5% | 47.9% | 24.2% |
| MiniMax M3 | 28.0% | 26.8% | 15.8% |
| Gemma 4 26B A4B | 22.4% | 22.6% | 17.7% |
| Gemma 4 31B | 21.5% | 20.0% | 14.6% |
Dense screens separate the leading models differently from the aggregate score. Gemini 3.5 Flash recovers 80 of 260 dense-screen issues, ahead of Kimi's 68 and Codex's 63. Kimi and Codex remain stronger on single- and multi-issue screens.
7.5 Category Breakdown
| Defect Tag | Best Model | Best Recall |
|---|---|---|
Color/Background | Kimi K2.7 Code + Together recovery | 40.8% (69/169) |
Icon/Nav | Kimi K2.7 Code + Together recovery | 40.4% (69/171) |
Image/Asset | Gemini 3.5 Flash | 76.7% (23/30) |
Missing Content | Gemini 3.5 Flash | 69.1% (67/97) |
Shape/Size | Codex GPT-5.5 xhigh | 51.9% (56/108) |
Spacing/Layout | Codex GPT-5.5 xhigh | 62.7% (69/110) |
Typography | Kimi K2.7 Code + Together recovery | 20.0% (18/90) |
Separator | Codex GPT-5.5 xhigh | 35.0% (7/20) |
Extra Element | Gemini 3.5 Flash | 60.0% (3/5) |
Selected/Disabled State | Kimi K2.7 Code + Together recovery and Gemini 3.5 Flash | 66.7% (4/6) |
Two rare tags with fewer than five scored annotations (other, 4 issues, and badimage, 1 issue) are omitted from this table.
Generated Study Tables
These tables are rendered from the current dataset, score, and prediction artifacts so the web paper can be checked against the executable study state.
Dataset Snapshot
- Rows
- 311
- Visual-diff pairs
- 234
- No-tagged controls
- 77
- Tagged issues
- 557
Sources: data/idf_eval.jsonl and reports/pilot/idf_pilot_15x4.jsonl
60-Row Hosted Pilot
| Model | Coverage | Known-Issue Recall | Diff Screen Recall | No-Tagged Flag Rate | Diagnostic Precision | Unmatched Predictions |
|---|---|---|---|---|---|---|
MiniMax M3results/minimax-m3-pilot/scores.json | 60/60 | 16.4% (23/140) | 40.0% (18/45) | 86.7% (13/15) | 10.8% (23/212) | 189 |
Gemma 4 31Bresults/gemma-4-31b-pilot/scores.json | 60/60 | 11.4% (16/140) | 28.9% (13/45) | 100.0% (15/15) | 11.0% (16/146) | 130 |
Gemma 4 26B A4Bresults/gemma-4-26b-a4b-pilot/scores.json | 60/60 | 15.7% (22/140) | 31.1% (14/45) | 100.0% (15/15) | 12.1% (22/182) | 160 |
Kimi K2.7 Coderesults/kimi-k2.7-code-pilot/scores.json | 60/60 | 23.6% (33/140) | 48.9% (22/45) | 60.0% (9/15) | 19.6% (33/168) | 135 |
Completed Full Runs
| Model | Coverage | Known-Issue Recall | Diff Screen Recall | No-Tagged Flag Rate | Diagnostic Precision | Unmatched Predictions |
|---|---|---|---|---|---|---|
Kimi K2.7 Code + Together recoveryresults/kimi-k2.7-code-full-combined-20260628-retryfix2-together-20260702/scores.json | 311/311 | 38.2% (213/557) | 65.8% (154/234) | 100.0% (77/77) | 15.9% (213/1340) | 1127 |
Gemini 3.5 Flashresults/gemini-3.5-flash-full-20260703/scores.json | 311/311 | 37.5% (209/557) | 62.4% (146/234) | 96.1% (74/77) | 20.2% (209/1033) | 824 |
Codex GPT-5.5 xhighresults/codex-cli-gpt-5.5-xhigh-full-20260701/scores.json | 311/311 | 37.3% (208/557) | 64.5% (151/234) | 98.7% (76/77) | 13.6% (208/1530) | 1322 |
MiniMax M3results/minimax-m3-full-combined-20260628/scores.json | 311/311 | 21.9% (122/557) | 40.6% (95/234) | 93.5% (72/77) | 11.5% (122/1065) | 943 |
Gemma 4 26B A4Bresults/gemma-4-26b-a4b-full-combined-20260628/scores.json | 311/311 | 20.3% (113/557) | 35.9% (84/234) | 85.7% (66/77) | 12.4% (113/913) | 800 |
Gemma 4 31Bresults/gemma-4-31b-full-combined-20260628/scores.json | 311/311 | 17.8% (99/557) | 32.5% (76/234) | 79.2% (61/77) | 13.3% (99/744) | 645 |
Prediction Format Health
| Model | Rows | Valid JSON | Empty | Malformed |
|---|---|---|---|---|
Kimi K2.7 Code + Together recoveryresults/kimi-k2.7-code-full-combined-20260628-retryfix2-together-20260702/predictions.jsonl | 311 | 311 | 0 | 0 |
Gemini 3.5 Flashresults/gemini-3.5-flash-full-20260703/predictions.jsonl | 311 | 311 | 0 | 0 |
Codex GPT-5.5 xhighresults/codex-cli-gpt-5.5-xhigh-full-20260701/predictions.jsonl | 311 | 311 | 0 | 0 |
MiniMax M3results/minimax-m3-full-combined-20260628/predictions.jsonl | 311 | 310 | 0 | 1 |
Gemma 4 26B A4Bresults/gemma-4-26b-a4b-full-combined-20260628/predictions.jsonl | 311 | 311 | 0 | 0 |
Gemma 4 31Bresults/gemma-4-31b-full-combined-20260628/predictions.jsonl | 311 | 311 | 0 | 0 |
Unmatched Prediction Audit
These rows are diagnostic review queues. They are not primary-score false positives under the recall-first protocol.
| Model | Audit Rows | CSV Artifact |
|---|---|---|
| MiniMax M3 | 189 | reports/pilot/minimax-m3-15x4-unmatched-predictions.csv |
| Gemma 4 31B | 130 | reports/pilot/gemma-4-31b-15x4-unmatched-predictions.csv |
| Gemma 4 26B A4B | 160 | reports/pilot/gemma-4-26b-a4b-15x4-unmatched-predictions.csv |
| Kimi K2.7 Code | 135 | reports/pilot/kimi-k2.7-code-15x4-unmatched-predictions.csv |
Visual Examples
These figures mirror the annotation interface: reference and generated screenshots are shown side by side, with an issue-level model result matrix below.
A dense visual-diff example where several models recover at least one known issue, but issue-level recall remains incomplete.
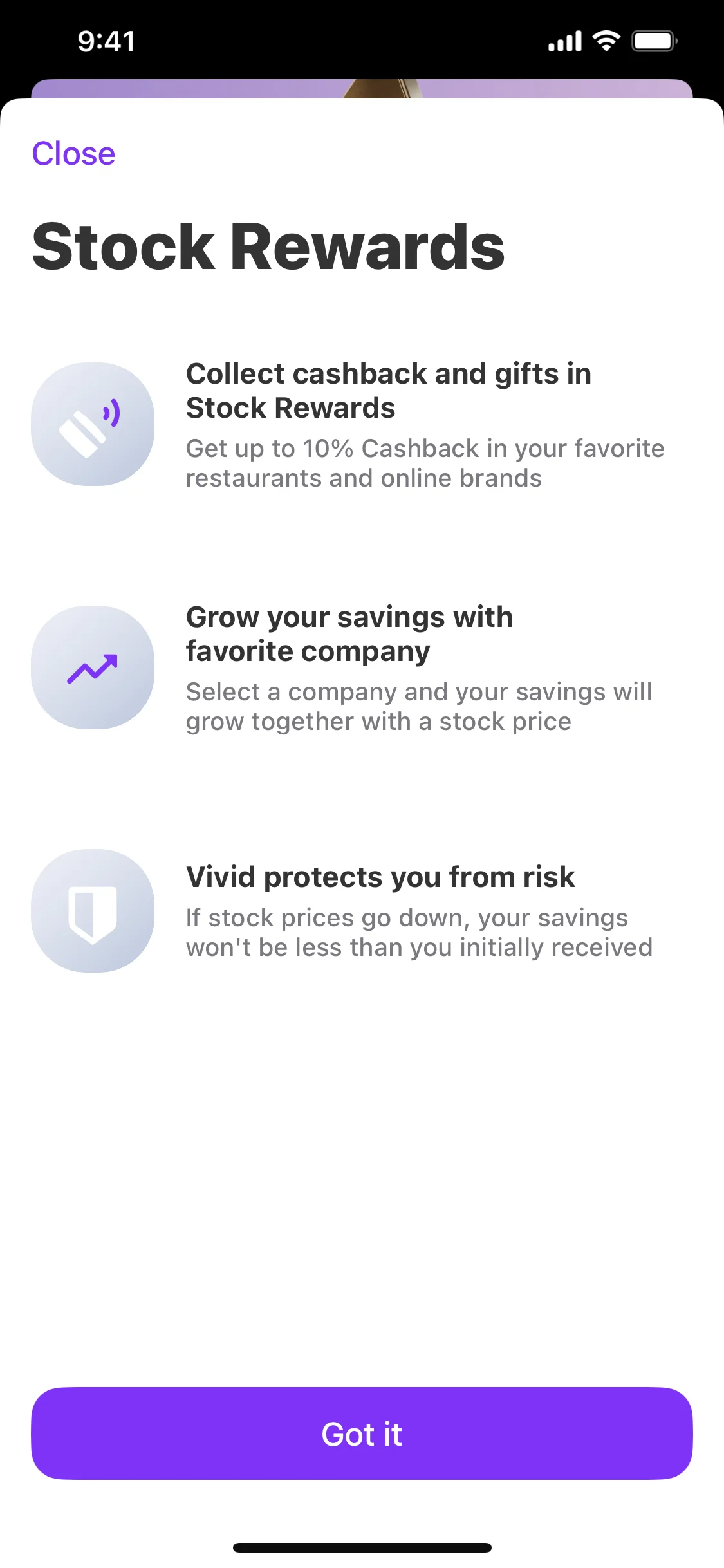 1234
1234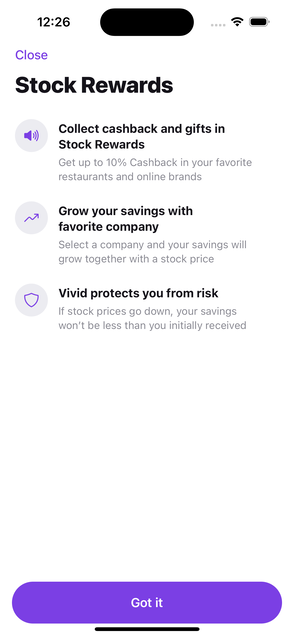 1234
1234| Human issue | Kimi K2.7 Code | Gemini 3.5 Flash | Codex GPT-5.5 | MiniMax M3 | Gemma 4 26B A4B | Gemma 4 31B |
|---|---|---|---|---|---|---|
Issue #1#835 No note; scored from tag and box. | FoundImage A IoU 0.77, pred #3 | FoundImage A IoU 0.88, pred #1 | Not found5 screen predictions | FoundImage B IoU 0.40, pred #3 | FoundImage A IoU 0.79, pred #1 | FoundImage B IoU 0.78, pred #1 |
Issue #2#836 No note; scored from tag and box. | Not found5 screen predictions | FoundImage A IoU 0.84, pred #2 | Not found5 screen predictions | Not found4 screen predictions | FoundImage A IoU 0.73, pred #2 | FoundImage B IoU 0.75, pred #2 |
Issue #3#837 No note; scored from tag and box. | Not found5 screen predictions | FoundImage A IoU 0.84, pred #3 | FoundImage A IoU 0.21, pred #3 | Not found4 screen predictions | FoundImage A IoU 0.73, pred #3 | Not found4 screen predictions |
Issue #4#838 No note; scored from tag and box. | FoundImage A IoU 0.71, pred #5 | Not found3 screen predictions | FoundImage A IoU 0.88, pred #5 | FoundImage A IoU 0.67, pred #4 | Not found3 screen predictions | Not found4 screen predictions |
A no-tagged control used to inspect over-flagging behavior. Some model findings may still be valid, so these are diagnostics rather than primary-score penalties.
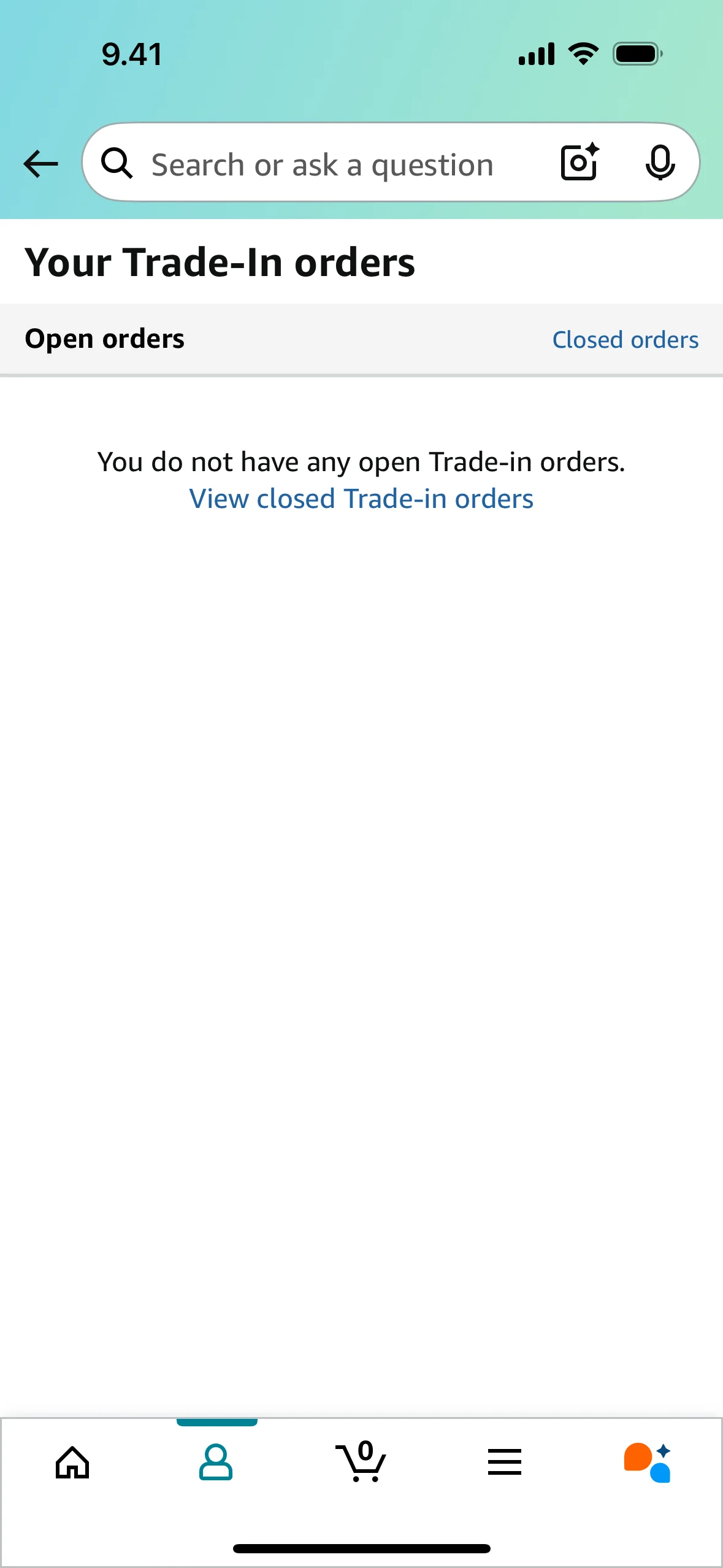
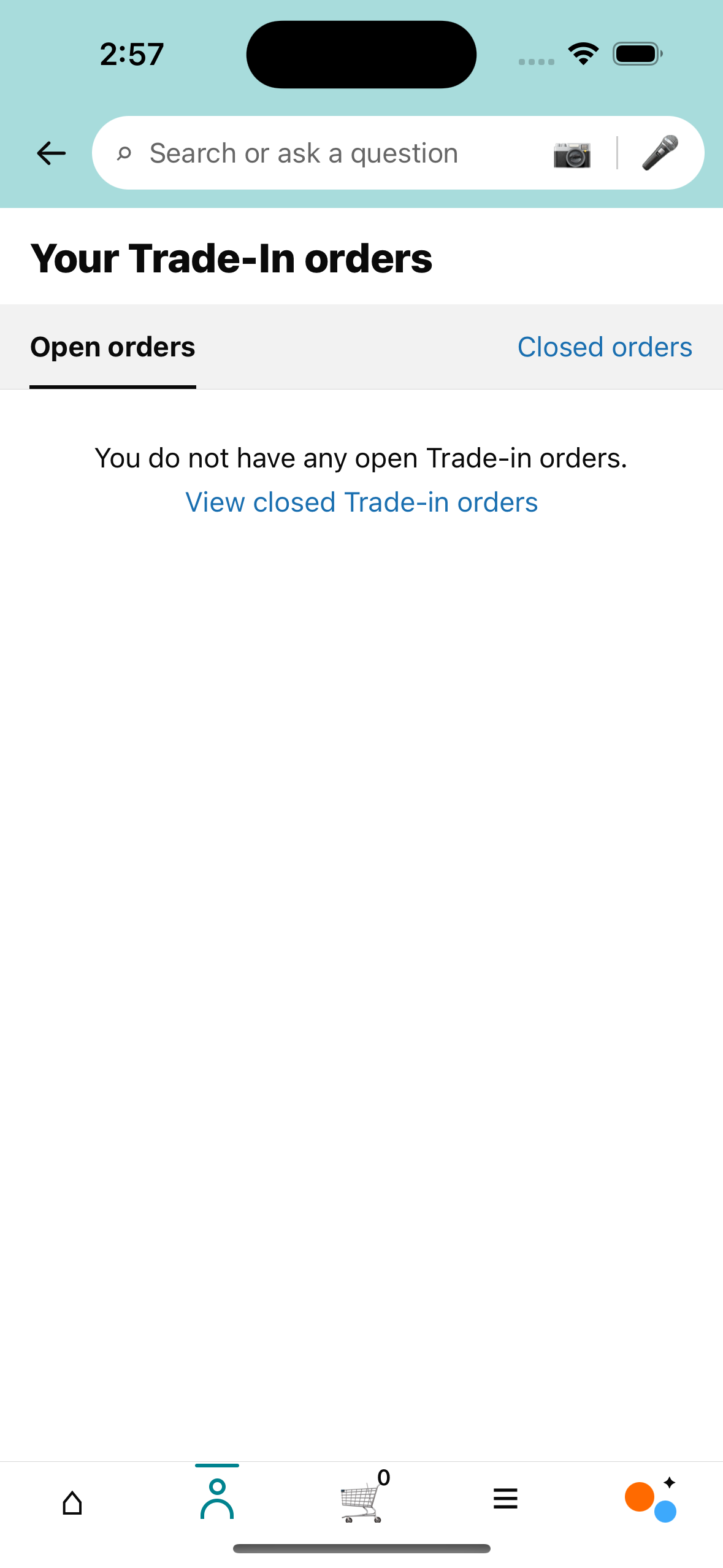
| Human issue | Kimi K2.7 Code | Gemini 3.5 Flash | Codex GPT-5.5 | MiniMax M3 | Gemma 4 26B A4B | Gemma 4 31B |
|---|---|---|---|---|---|---|
No scored human issue No tagged human issue is available for this control screen. | Flagged 5No scored human issue in this row | Flagged 3No scored human issue in this row | Flagged 5No scored human issue in this row | No issue predictedMatched no-diff control | Flagged 4No scored human issue in this row | Flagged 3No scored human issue in this row |
8. Analysis
The full benchmark shows four recurring patterns.
First, screen-level detection is easier than issue-level recall. A model can notice that a screen differs while still missing most annotated defects on that screen. This is especially visible on dense examples, where recovering one issue counts for screen recall but leaves many known issues unmatched. The leading models reach 62-66% diff-screen recall, but only 37-38% known-issue recall.
Second, defect families vary in difficulty. The strongest category results are on Image/Asset and Missing Content, where Gemini 3.5 Flash recovers 76.7% and 69.1% of known issues. Frequent subtle categories remain harder: Typography tops out at 20.0%, Icon/Nav at 40.4%, and Color/Background at 40.8%. This is consistent with the visual nature of the task: missing content and changed illustrations often occupy larger, more semantically distinct regions, while typography, color, and icon differences can be small and localized.
Third, abstention is difficult. The no-tagged controls are not guaranteed clean, but they still reveal a practical behavior: every high-recall model reports issues on nearly every no-tagged control. Kimi flags 77 of 77 no-tagged controls, Codex flags 76 of 77, and Gemini flags 74 of 77. Under the recall-first protocol, this does not reduce known-issue recall, but it matters for product usability because a review tool that flags every screen requires substantial human triage.
Fourth, precision and recall trade off differently across models. Kimi K2.7 Code with Together recovery has the highest known-issue recall, but Gemini 3.5 Flash produces fewer unmatched predictions and has the best F1. Codex is nearly tied on recall but produces the largest prediction set, lowering diagnostic precision. The Gemma runs are more conservative and have better no-diff specificity, but they miss substantially more known issues.
The Kimi K2.7 Code run also adds a serving lesson: response format and route stability are part of benchmark performance. Even after OpenRouter-side retry passes, the OpenRouter full artifact had 142 failed rows. Retrying those rows through Together AI yielded a clean 311-row prediction file and changed Kimi from an output-health failure case into the highest-recall run. This should be reported as model-plus-route recovery, not as a clean single-endpoint result.
9. Limitations
The human annotations are known positives, not exhaustive ground truth. A model can identify a real issue that a human annotator missed. For this reason, unmatched predicted issues are diagnostics rather than primary false positives.
No-tagged controls are inferred from completed screens with zero scored tagged issues. They should not be treated as guaranteed defect-free. A future release should include a manual audit pass for no-tagged controls before making strong specificity claims.
The current split names measure issue density, not visual difficulty. A single-issue screen can still be hard if the issue is subtle, and a dense screen can be easy if all issues are large and obvious.
The multi-model comparison now covers the full 311-row set for MiniMax M3, Gemma 4 31B, Gemma 4 26B A4B, Kimi K2.7 Code with Together recovery, Gemini 3.5 Flash, and Codex GPT-5.5 xhigh. These runs are not all identical deployment conditions: Kimi combines OpenRouter and Together retry recovery, Gemini uses Google's OpenAI-compatible endpoint, and Codex uses the Codex CLI. The benchmark therefore compares practical eval runs, not isolated model weights under a single serving stack.
The current scoring is intentionally recall-first. Diagnostic precision is computed against known human annotations, but unmatched model predictions may include real defects missed by annotators. Precision and no-diff specificity should therefore be treated as operational diagnostics until unmatched findings and no-tagged controls receive a separate human audit.
10. Reproducibility and Release
The benchmark is represented as JSONL. Each row contains pair metadata, paths to Image A and Image B, the density split, and human ground-truth issues with tags and normalized boxes. Prediction files are also JSONL, with one model output per input row. Artifact filenames retain the benchmark's historical idf prefix, for example data/idf_eval.jsonl.
The core reproducibility flow is:
python scripts/build_dataset.py --output data/idf_eval.jsonl
python scripts/make_pilot_dataset.py \
--dataset data/idf_eval.jsonl \
--output reports/pilot/idf_pilot_15x4.jsonl \
--manifest reports/pilot/idf_pilot_15x4.manifest.json \
--per-bucket 15
python scripts/evaluate.py \
--dataset reports/pilot/idf_pilot_15x4.jsonl \
--predictions results/<model>-pilot/predictions.jsonl \
--judge-provider tag_box \
--judged-output results/<model>-pilot/judged.jsonl \
--output results/<model>-pilot/scores.jsonFor the current study snapshot, the repository also emits a machine-readable manifest that records dataset summaries, score summaries, audit queue sizes, paper sections, core documentation, reproducibility scripts, byte sizes, and SHA-256 hashes. The manifest can be regenerated and checked with:
python scripts/make_study_manifest.py \
--output-json reports/study_manifest.json \
--output-md docs/study_manifest.md
python scripts/check_study_manifest.py \
--manifest reports/study_manifest.jsonThe current manifest validates the local study artifacts, including the 311-row full dataset, the 60-row pilot dataset, four hosted pilot score sets, the six completed full runs, unmatched-prediction audit CSVs, output-health reports, paper markdown sections, and reproducibility scripts.
Hand-written report tables are checked against the score JSON files with:
python scripts/check_report_numbers.pyThe unmatched-prediction audit is a secondary human-review layer. The web audit page can export and re-import decision JSON, and the exported decisions can be summarized with:
python scripts/summarize_audit_decisions.py \
--decisions path/to/idf-unmatched-audit-decisions.json \
--output-json reports/pilot/unmatched-audit-decisions.json \
--output-md reports/pilot/unmatched-audit-decisions.mdThe release package should include dataset JSONL, copied image assets or stable image references, score scripts, prompt templates, and a small example submission. A public release should also document the no-tagged control caveat and the recall-first interpretation of unmatched model predictions. Unmatched prediction CSVs should be treated as human audit queues rather than primary false-positive labels.
11. Conclusion
Scry Design Diff Eval evaluates VLMs as localized mobile UI regression reviewers. The task is intentionally stricter than captioning or broad screen-level comparison: a model must output a defect list with matching tags and boxes.
The current results show that VLM endpoints can recover many known UI defects, but still miss most human-tagged issues under deterministic tag-and-box scoring. On the full 311-pair benchmark, Kimi K2.7 Code with Together recovery reaches 38.2% known-issue recall, Gemini 3.5 Flash reaches 37.5%, and Codex GPT-5.5 xhigh reaches 37.3%. Gemini is the strongest balanced run in this snapshot because it keeps recall near the top while producing fewer unmatched predictions and the highest F1.
These numbers leave substantial room for improvement in fine-grained comparison, localization, structured output reliability, and calibrated abstention. The most recall-capable models still flag nearly every no-tagged control, which is acceptable for a recall-first benchmark but costly for a production review workflow.
The benchmark is most useful when read as a recall-first review aid evaluation: it measures how many known human issues a model catches, while preserving extra model findings for separate human analysis.
References
- Linhao Zhang, Aiwei Liu, Yuan Liu, and Xiao Zhou. "DiffSpot: Can VLMs Spot
Fine-Grained Visual Differences in Web Interfaces?" arXiv:2605.29615, 2026.
- Scry Design Diff Eval repository artifacts used by this draft:
docs/study_results.md, docs/openrouter_15x4_results.md, docs/study_manifest.md, reports/study_manifest.json, reports/pilot/idf_pilot_15x4.jsonl, results/*-pilot/scores.json, scripts/make_study_manifest.py, scripts/check_study_manifest.py, scripts/check_report_numbers.py, and scripts/summarize_audit_decisions.py.